Dealing with Outliers in Data Science: Techniques and Best Practices
Outliers, or data points that deviate significantly from the norm, can have a significant impact on data analysis and modeling results. Properly handling outliers is crucial for ensuring the accuracy and reliability of findings in data science tasks.

Introduction
Data science is a rapidly growing field that involves analyzing and interpreting large amounts of data to uncover insights, make informed decisions, and build predictive models. However, real-world data is often imperfect and can contain errors or unusual observations that deviate significantly from the norm, known as outliers. Outliers can negatively impact data analysis and machine learning models, leading to inaccurate results or biased predictions. Therefore, dealing with outliers is a critical step in the data preprocessing stage in data science. In this article, we will explore the concept of outliers, their impact on data analysis and modeling, and various techniques and best practices for handling outliers in data science.
Outliers
Outliers are data points that differ significantly from the majority of the data points in a dataset. They are values that fall outside the expected or usual range of values for a particular variable. Outliers can occur for various reasons, such as measurement errors, data entry errors, sensor malfunctions, or genuinely unusual observations in the underlying data generating process. Outliers can distort statistical measures, such as mean and standard deviation, leading to inaccurate summaries of the data and misleading conclusions.

Impact of Outliers on Data Analysis and Modeling:
Outliers can have a significant impact on data analysis and modeling results. They can skew statistical measures, leading to inaccurate estimates of central tendency and dispersion. For example, if a dataset of employee salaries contains a few extremely high salaries due to executive bonuses, the mean salary can be significantly inflated, leading to an overestimated average salary for the organization. Similarly, if a dataset of housing prices contains a few very low prices due to data entry errors, the median price may not accurately represent the typical price of houses in that area.
Outliers can also affect the performance of machine learning models. Some models, such as linear regression, are sensitive to outliers, as they are based on minimizing the sum of squared errors. Outliers with large residuals can disproportionately influence the model’s parameter estimates, leading to biased predictions. For example, in a model that predicts house prices based on features such as square footage and number of bedrooms, an outlier with an unusually high price may strongly impact the regression line, resulting in an inflated predicted price for similar houses. On the other hand, some models, such as decision trees and random forests, are more robust to outliers as they make decisions based on splits that are not affected by individual data points. However, outliers can still impact the tree-building process by affecting the purity of split decisions or the tree’s structure.

Techniques for Detecting Outliers:
Handling outliers is an important step in the data preprocessing stage in data science. There are several common techniques that can be used to deal with outliers, depending on the specific dataset, the analysis or modeling technique being used, and the underlying domain knowledge. Let’s explore some of these techniques in detail:
The first step in dealing with outliers is to detect them in the dataset. There are several statistical techniques that can be used for outlier detection, such as:
- Box plots: Box plots, also known as whisker plots, can visually display the distribution of data and identify potential outliers. In a box plot, the box represents the interquartile range (IQR), which contains the middle 50% of the data, and the whiskers represent the data points within 1.5 times the IQR from the upper and lower quartiles. Data points outside this range are considered potential outliers and are plotted as individual points.

- Scatter plots: Scatter plots can be used to identify outliers in bivariate datasets, where two variables are plotted against each other. Outliers can be identified as data points that deviate significantly from the general pattern of the scatter plot.
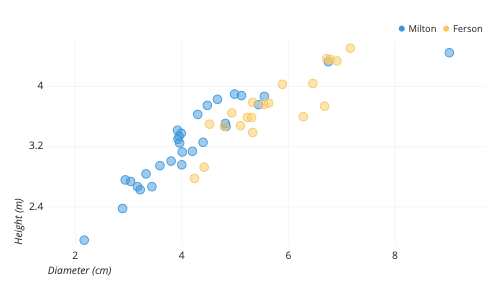
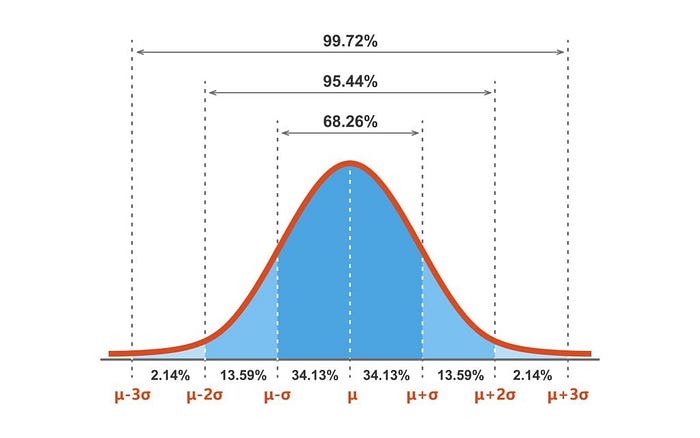
- Z-score: The Z-score is a measure that indicates how far a data point is from the mean of the dataset in terms of standard deviations. Z-score can be calculated for each data point and those with a Z-score above a certain threshold (e.g., 2 or 3) can be flagged as potential outliers.
- Statistical tests: Various statistical tests, such as the Grubbs’ test, Anderson-Darling test, or the Mahalanobis distance, can be used to detect outliers based on the assumption that the data follows a certain distribution or multivariate distribution. These tests can identify data points that deviate significantly from the expected distribution or relationship between variables.
Handling Techniques:
- Once outliers are detected, there are several techniques that can be used to handle them, depending on the nature of the data and the analysis or modeling technique being used. Some of the common handling techniques are:
- Imputation: Imputation involves replacing or filling in the outlier values with estimated or imputed values. This can be done using various methods, such as replacing outliers with the mean, median, or mode of the dataset, or using more advanced techniques such as k-nearest neighbors imputation or regression imputation, where imputed values are estimated based on the values of neighboring data points or by regressing on other variables in the dataset.
- Transformation: Transformation involves applying mathematical transformations to the data to reduce the impact of outliers. For example, taking the logarithm, square root, or cube root of the data can compress the scale of the data and reduce the influence of extreme values. However, transformation should be done with caution, as it can also affect the interpretation and validity of the results.
- Winsorizing: Winsorizing involves capping or truncating the extreme values at a certain threshold. For example, values above a certain percentile (e.g., 95th percentile) can be set to the value of the percentile, and values below a certain percentile (e.g., 5th percentile) can be set to the value of the percentile. This can be done to reduce the impact of extreme values without completely removing them from the dataset.
- Data partitioning: Another approach is to partition the data into different subsets based on the presence of outliers. For example, one can create separate subsets of data with and without outliers and analyze or model them separately. This can provide insights into the differences in data patterns or model performance with and without outliers.
Best Practices for Handling Outliers:
Dealing with outliers requires careful consideration and understanding of the data and the specific analysis or modeling technique being used. Here are some best practices for handling outliers in data science:
- Understand the data: It’s important to have a deep understanding of the data, its context, and the domain knowledge before dealing with outliers. This includes understanding the data generating process, the measurement errors or biases, and the expected range of values for each variable. Understanding the data can help in identifying and interpreting outliers appropriately.
- Use multiple detection techniques: Different detection techniques may yield different results, so it’s recommended to use multiple techniques to detect outliers. This can help in identifying potential outliers from different perspectives and increase the accuracy of outlier detection.
- Consider the impact of outliers: It’s important to carefully evaluate the impact of outliers on the analysis or modeling results. Some outliers may carry important information or represent genuine anomalies in the data, while others may be measurement errors or data entry errors. Understanding the impact of outliers can help in deciding the appropriate handling technique.
Conclusion
Outliers are an important consideration in data analysis and modeling, as they can significantly impact the results and interpretation of findings. Detecting and handling outliers requires careful consideration of the data, the analysis or modeling technique being used, and the specific context of the problem. There are various techniques available for detecting and handling outliers, and the appropriate approach may vary depending on the data and the specific situation. Best practices for handling outliers include understanding the data, using multiple detection techniques, considering the impact of outliers, choosing appropriate handling techniques, documenting the handling process, evaluating the impact of handling techniques, being cautious with extreme values, and considering the impact on model performance. By following these best practices, data scientists can effectively manage outliers in their analysis and modeling tasks, leading to more accurate and reliable results.
